背景
最近三个月,我尝试构建一个 pixel-level generator,这从某种方面是为了追寻研究热点,从另一个方面也是为了探究以下几个问题: 1:一个生成器到底能不能生成pixel? 2:Pixel Gen能生成到什么地步? 3:PixelGen和传统的生成latent到底有啥区别? 有啥意义?
我相信第一个问题已经被解决,最近有很多工作已然出现,包括Tianhong的JiT,DeCo以及PixelDiT,它们的实验和代码都告诉我们一个明确的事儿:PixelGen可以搞,效果虽然比不上SOTA的latentGen,但是也不差。
既然同行的先锋队伍已经证明这条路线能走,那我们到底走不走呢?我还是深信实践出真知的道理,我们需要自己来搭建一个pixel gen来试试。 在搭建的过程中,我们自然能对PixelGen的能力边界,和传统的方法的区别有自己的理解。也就是说,我们需要在实验中回答第二个问题和第三个问题。
What I Tried
为了全面理解PixelGen范式的力量,我设计了两个naive的idea。 既可以浅试PixelGen的力量,同时也可以实践出真知,检验我学习的成果。 如果这几个idea能开花结果,那就更好了。 另外,这两个idea分别做的是Pixel Diff和Pixel AR。 这是因为在我的思考中,PixelGen如果有好处,有作用,那么就不应该被限定于Diff框架,而是有利于所有的生成器,只要它们最后回归的是pixel就行了。
方法 A:DINO 微调作为 pixel generator
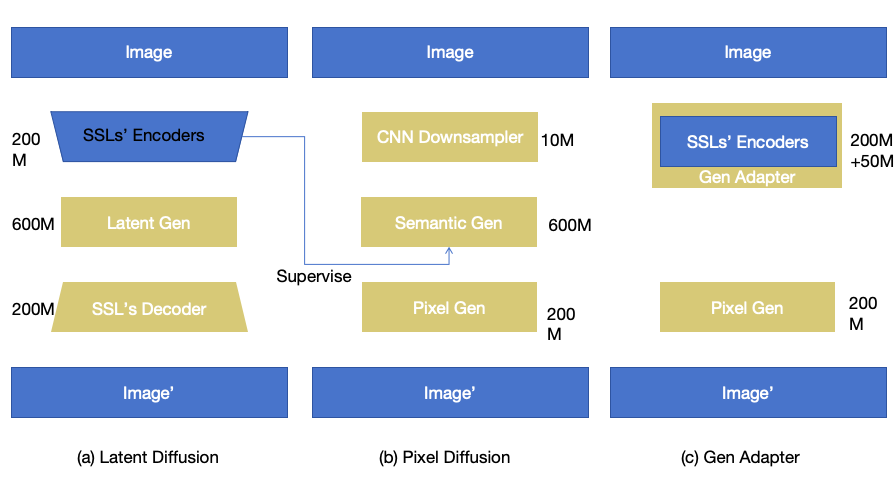
一句话说明这个idea:既然输入都是pixel了,那我们想要完成生成任务,就可以微调一个DINOv3的encoder,让它支持noised输入就完事了。 输出的特征就保持DINOv3的特征就行了,反正不管是RAE还是PixelDiT都会训练一个pixel gen/ dino decoder来解码生成的语义信息。
这个idea同时还启发于REPA的训练方法,我们如果使用了DINO的特征来监督diff的中间特征(如图中的这个蓝色系线),那么可以理解为如下的objective: 我们希望 diffusion 模型在某一中间层提取的表示,与干净图像的 DINO 特征对齐:
\[h_\theta(x_t, t) \approx \text{DINO_teacher}(x_0),\]其中 $h_\theta(\cdot)$ 表示 diffusion 模型的中间特征,$\text{DINO_teacher}(x_0)$ 表示冻结的 DINO encoder,$x_t$ 是噪声图像,$x_0$ 是对应的干净图像。
如果把这个目标再往前推一步,其实可以得到一个更直接的形式: 我们可以直接微调一个 DINO-style encoder,使其对噪声图像也保持语义一致, 即:
\[\text{DINO_student}(x_t,t) \approx \text{DINO_teacher}(x_0),\]其中$\text{DINO_student}(x_t,t)$ 是我们要微调的学生模型, 初始化来自于DINO_teacher相同的权重,t的信息输入则转化为一个简单的token扔在dino的prefix前面(DINO的输入本身包含了一个cls token和几个register tokens,我们只是增加了一个额外的token)。
从这个角度看,DINO_student作为pixel-space diffusion的话,在极限情况 $t \to 0$ 本身就是一个“完美解”:
\[\text{DINO_student}(x_t,t) = \text{DINO_teacher}(x_0).\]换句话说,在pixel空间的输入情况下,t->0时候,dino本身就是一个完美的生成器(因为能稳定获得dino(clean_x)), 所以我们微调它,让它在t更大的时候起点作用就行了。
为什么没有人微调感知器为生成器
这个想法简单的离奇,我却又在想,为什么在传统的latent diffusion训练中并没有如此的思路呢?应该是传统的latent diff的输入与DINO不一致:它们不是图像输入,无法直接微调DINO网络来完成自己的任务。
实验
复现
我们首先自己复现了一下PixelDiT这篇文章。为什么不选择JIT或者DeCo呢?这单纯是我觉得这篇文章的不强制x-pred,我们可以用之前的v-pred代码,其次设置非常简单干净,没有啥额外的损失或者trick。 但是由于其代码并没有开源,我们就根据paper中的公式进行了实现,效果到底差多少也没有具体验证,反正我并不是为了刷SOTA,只是为了验证idea,所以能跑起来就算赢。
我的实现没有任何的特别的trick:pixel的输入阶段就是用了最简单的1D CNN输入(步长和kernel size都设置为patch的像素数量,一般就是16$$16=256),然后接一段和传统latent diff一模一样的几十个trans blocks。
最后再在每个输出的latent后面接上一个4层的超级轻量pixel diff就行了。pixel diff的trans block有特别的设计,就是PixelDit中的global attn,实现起来也特别简单。
使用4张H100,用bs$644$的设置训练了187500iteration(总计为38个epoch),结果如下:
 哇哦,初看居然还可以。整体来说training和inference都很稳定。我很满意baseline的效果,但是为了对其后面我们加入DINO微调的思路,我们新增加了REPA的实现:
哇哦,初看居然还可以。整体来说training和inference都很稳定。我很满意baseline的效果,但是为了对其后面我们加入DINO微调的思路,我们新增加了REPA的实现:
 哇哦,加上REPA之后这效果更棒了。我说实话不错啊,虽然和sota方法有区别。为了大家有个直观感受,我提供一个FID为1.27的AR在同样训练条件下的结果吧:
哇哦,加上REPA之后这效果更棒了。我说实话不错啊,虽然和sota方法有区别。为了大家有个直观感受,我提供一个FID为1.27的AR在同样训练条件下的结果吧:
 可以看到PixelDiT的结果还是细节模糊 但是整体语义结构比FID为1.27的AR会好一些,再加上diff本身训练就很慢,如果训练到800Epoch的话,效果应该会很惊艳。
可以看到PixelDiT的结果还是细节模糊 但是整体语义结构比FID为1.27的AR会好一些,再加上diff本身训练就很慢,如果训练到800Epoch的话,效果应该会很惊艳。
这次试验也让我有了一个非常明显的intuition:PixelGen还真行!可以跑,很简单,不难,效果可以。
输入端由单层CNN改为DINOv3-S
接下来我们开始尝试将DINOv3-S给微调成为一个语义生成器,用来替代PixelDit中的semantic blocks。
 我只能说,差距不大。
我只能说,差距不大。
问题
在后续的实验中,我们发现了用DINO处理noised输入并没有特别的效果,让我们对diff的生成好像理解得更深了:
- DINO很小诶,只有20M-200M参数,它能用LORA微调成为一个生成器吗?
我仔细思考之后认为,DINOv3-S并不能微调成为一个生成器。原因如下:感知是一个绝对的单峰任务。虽然噪声加的不大的情况下,diff就是一个单峰任务,但这不包括t->1的时候。 此时我们的网络需要学习从噪声到manifold上所有可能是目标样本的地方的方向,这个绝对是一个多峰问题。 换句话说,在t->1的时候,就算是强行记忆这些信息,需要的参数也不止20M。但是如果我们在200M级别的S上做,参数空间应该能勉强够用。
- 虽然DINO在t->0的时候是一个完美的(输入pixel 输出latent的)diff,但是t->1的时候不才是diff任务最难的部分么。
没错,但是我们发现使用了DINO-S替代CNN输入之后,REPA loss下降的比较多,比较快,说明微调DINO确实能处理噪声输入,也就是0<t<1的情况下,它还是有点帮助PixelDiT学习REPA的作用。
- 更低的REPA损失,也就是代表着更好的DINO语义空间的去噪声效果,会不会帮助更好的生成最终pixel结果呢?
实验告诉我们,可能不会。这大概率是因为语义空间的优化和像素空间的优化还是有一定的差别,也许pixel diff需要的语义并不绝对=DINOv3的特征。但是如果在RAE的环境下,确实能帮助更好的生成。可惜RAE的输入也是DINO特征,并不能复用DINO这个输入是像素的网络。